
We’ve come a long way from this “man-machine” approach 60 years ago. Today, with Amazon’s computer vision platform called Amazon Rekognition, we can have machines naming every person in a group photo, identify celebrities in videos, and analyze a person’s gender, age, and even emotions with one image. Beyond human faces, image recognition can now label every component of your photo: a human subject, a bike, mountains, rocks, and the view behind them.

Image from AWS
How does Amazon Rekognition work?
When humans see an image, we interpret and recognize its components. We can tell from a photo of my pets which one is the dog and which one is the cat. We know this because we’ve spent our kindergarten years naming animals. Watching nature channels and our trips to the zoo have validated all these learnings.
Unfortunately, computers did not go to kindergarten, so we have to teach them to understand our world through an input device: a camera. Then we have to teach them what a dog is, how it is different from a cat, and which part of the picture is irrelevant.
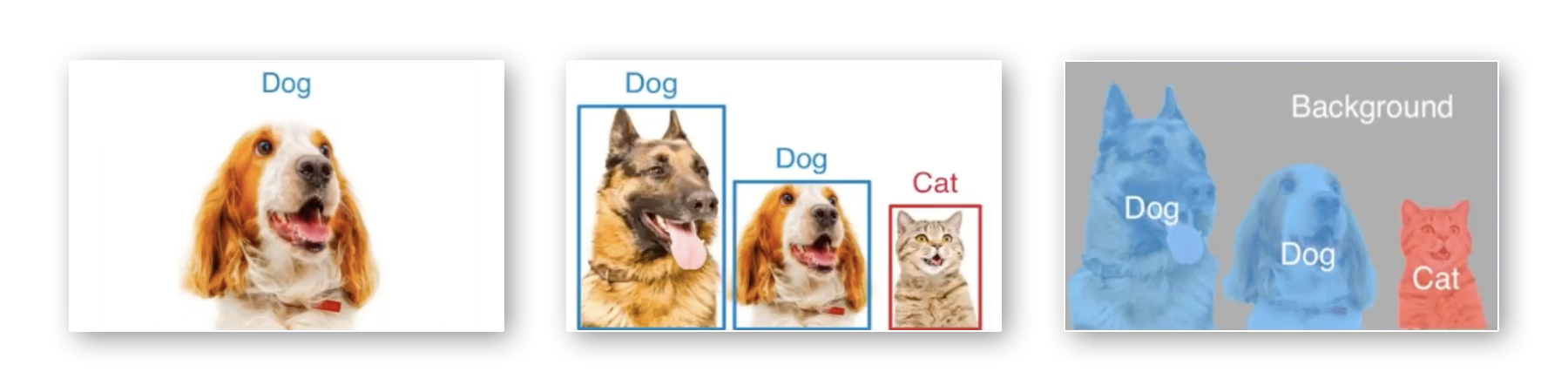
Image from AWS
Amazon Rekognition is based on deep learning, a kind of machine learning that simulates how the human brain processes and makes decisions based on the information. By learning to see and understand, Amazon Rekognition automates tasks that require vision and do it at a massive scale.
The possibilities of Amazon Rekognition

Image from “Where’s Waldo?”
Hands down, Amazon Rekognition will beat any human being at a game of “Where’s Waldo?”. But Amazon Rekognition can be useful in multiple industries as well.
In the media
- Automate metadata extraction from image and video files based on objects, faces, text, and more. With a detailed and precise metadata library, it will be a breeze to search for one specific video file from a mountain of media assets.
- Flag nudity, violence, weapons, and other inappropriate content. Customize how you will present such content depending on the policies applicable to an audience segment.
- Identify the start and end of a shot, black frames, and beginning and end credits. Speed up editing and content production without having to wade through hours of video footage.
In branding and content
- Review user-generated content in your social media, video streaming, and even matchmaking platforms. Make sure your brand is safe from disturbing content despite the large volume of uploaded files.
- Filter out unwanted associations with your brand such as alcohol or violence in the news, media, or e-commerce platforms.
In workplace safety
- Detect usage of personal protective equipment (PPE) in your facility and whether they are being worn correctly: masks worn over the nose, gloves covering the hands, etc.
- If you have custom PPEs specific to your workplace, simply upload a labeled image and let Amazon train the platform to recognize them.
You can start solving problems on computer vision today.
Only a few years ago, if you wanted to set up a deep learning-based photo and video analysis platform for your organization, you would need billions of images, thousands of man-hours, and enormous compute power. Not to mention a budget to sustain such a project.
Today, with Amazon Rekognition, you can leverage Amazon AI that experts have built, developed, and taught all these years — and make computer vision work for you.
Interested in a consultation about computer vision? Fill out the form below.